
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 자바
- 개발자
- java8
- 자바8
- Stream
- lamda
- 스타트업
- 정규식
- 백엔드 강의
- CodeCommit
- java
- 백엔드 코딩
- Android
- 문돌이
- 코딩입문
- 오류제어
- thread
- 코딩독학방법
- RFC
- 데이터베이스기초
- 람다
- 자바자료구조
- 데이터베이스강의
- 안드로이드
- 스트림
- C포인터
- CodeLatte
- 백엔드 개발 코딩 강의
- 코드라떼
- 자료구조강의추천
- Today
- Total
이병록의 개발 블로그
TCP의 흐름제어, 오류제어, 혼잡제어 개념에 대한 개요 본문
최종 수정일: 2020-07-11

안녕하세요. 이번 문서는 TCP의 흐름 제어, 오류 제어, 혼잡 제어 개념과 개요에 대해 다루려고 합니다.
요즘 문서의 흐름이 좀 더 네트워크 프로토콜중 HTTP와 함께 TCP에 대한 내용을 작성중입니다.
이후에는 UDP 관련해서도 작성할 예정입니다.
후우..할 일이 많네요 요즘..^^;; 부지런해야 하는데 게으릅니다 하하하하!
해당 글에서 다루는 것은 다음과 같습니다.
1. HTTP와 TCP의 관계?
2. 간략 TCP 송신 버퍼, 수신 버퍼, 윈도우
2. 윈도우 알고리즘
- 송신측 흐름 제어를 위한 TCP의 윈도우들
- 송신측 Go-Back-N과 송신측 슬라이딩 윈도우
- 수신측 Go-Back-N과 수신 윈도우
- 송수신측 Go-Back-N과 윈도우 시나리오
- 송신측 Selective-Repeat과 송신 윈도우
- 수신측 Selective-Repeat과 수신 윈도우
- 송수신측 Selective-Repeat과 윈도우 시나리오
- Go-Back-N과 Selective-Repeat 혼합 방식 시나리오
2. TCP 흐름 제어
- 송신측 흐름 제어를 위한 TCP의 윈도우들
- 수신 윈도우 변경 간략 시나리오
- 송신 윈도우란?
- 송신측의 흐름 제어에 미치는 네이글 알고리즘
- 그럼 왜 네이글 알고리즘을 사용하는가?
- 네이글 알고리즘의 단점
3. TCP의 혼잡 제어
- 혼잡 윈도우 변수(cwnd)
4. TCP Reno 혼잡 제어 정책
- TCP Reno 혼잡 감지
- 동일한 세 개의 ACK 수신의 의미는?
- TCP Reno 혼잡 상태
5. TCP의 오류 제어
- 검사합(본문엔 설명 없음)
- 확인응답 정책과 방식
- 타임아웃
6. 기타 - OS TCP 파라미터
7. 남기는 말
TCP 흐름제어, 오류제어, 혼잡제어 가상 시나리오 예제
가상의 시나리오를 만들고 TCP 흐름제어, 오류제어, 혼잡제어 시나리오를 작성한 문서가 있습니다.
현대의 TCP 방식에 완전히 맞지는 않지만 대략적인 큰 흐름을 볼 수 있는 것에 도움이 될 것입니다.
해당 링크를 연결합니다.
본문을 가장 먼저 작성했으나, 공개는 시나리오 먼저 하긴 했습니다. 이유는 좀 더 정리를 할 필요가 있었고 좀 더 어떻게 쉽게 설명할 수 있을까 고민이 많았습니다. 혹시나 도움이 되길 바랍니다.
TCP의 흐름제어, 오류제어, 혼잡제어 예제 시나리오
최종 수정 일 : 2020-07-11 이 글을 작성한 이유는 다음과 같습니다. 1. TCP의 흐름제어, 오류제어, 혼잡제어를 별도의 개념을 따로따로 아는 것에 더하여 최대한 결합하여 이해해보자. (현재까지 가��
roka88.dev
들어가기전에

TCP 얘기하려다가 갑자기 왠 당근 사진이냐 하시는 분들도 있을 것 같습니다.
요즘 집에서 어무니께서 당근을 키우고 계시더군요. 허허이. (지금은 엄니의 분갈이 실 수로 목이꺾였습니다...ㅠ)
당근이 크는 것을 한 달간 지켜보긴 했는데, 이녀석이 재미있더군요.
일단 심어놓으면 거의 한 달 가까이 요지부동입니다.
위에서 풀때기가 자라지 않습니다. 그러더니 한 달쯤 후에는 갑자기 풀때기가 보이더니 엄청나게 쑥쑥커버립니다.
당근은 위에 풀때기가 자라기 위해 깊숙히 한 달 동안 뿌리를 내리더군요.
공부와 학습이라는 것도 그런 것 같습니다.
물론 바로 티가 날만한(바로 사용할 만한) 지식을 습득하면 티가 납니다만 일반적으로는 티가 잘 나지 않습니다.
그럼에도 인고의 시간, 뿌리를 내리는 시간이 지나다보면 분명 좋은 결과가 있을 것이라고 생각듭니다.
사자성어로도 '대기만성' 이라는 말이 있지요.
대기만성 - 큰 사람이 되기 위해서는 많은 노력과 시간이 필요함을 나타내는 말(출처 네이버)
조급함은 오히려 독이되니 이 글을 보시는 모든 분들이 편안한 마음을 가지고 사시길 기도하겠습니다.
이제 본론으로 들어가겠습니다.
HTTP와 TCP의 관계?
전 세계에서 가장 많이 사용하는 프로토콜중 하나는 HTTP이다.
HTTP는 전송계층의 TCP에 의존하고 있으며, HTTP에 대해서 깊은 이해를 하기 위해서는 TCP에 대해서 알아야 함은 틀림없다.
HTTP에 대한 어떤 깊은 이해를 말하는 것인가?
현 HTTP/2.0 까지는 전송 계층의 TCP를 기반으로 한다.
HTTP/3.0(가칭)은 전송 계층의 UDP를 기반으로 한다.
HTTP 프로토콜이 발전하는 이유를 아는 것과 함께 '효율적'으로 '잘' 쓰기 위함이다.
HTTP는 0.9 부터 HTTP/3.0(초안) 까지 업데이트 되어왔다.
왜 HTTP 프로토콜이 변화해야 할 수 밖에없는가.
그리고 왜 버전업을 하는가.
그 이유는 모두 성능과 비용최적화 때문이다.
일단 HTTP/2.0 까지는 기반 프로토콜인 TCP를 사용한다.
TCP 매커니즘에 대해서 잘 알면, 성능 최적화 및 비용을 줄이는 방법에 대한 이해와
더 나아가 새로운 프로토콜을 만들 수 있는 영감이 주어질 수 있다.
간략 TCP 송신 버퍼, 수신 버퍼, 윈도우

TCP의 컴포넌트라고 한다면, 몇 가지가 있다.
•송신버퍼 - 송신버퍼는 프로세스로 부터 생산된 데이터를 받아 수신측에 전송할 데이터를 보관하는 공간이라고 볼 수 있다.
•수신버퍼 - 수신버퍼는 송신측으로 부터 전송받은 데이터를 받아 보관하여, 수신 프로세스를 통해 데이터가 소비되는 공간이라고 볼 수 있다.
•윈도우(논리적 개념인) - 전송 중이거나, 전송 될 데이터의 세그먼트의 순서번호(sequence number) 또는 세그먼트를 포함하고 수신측의 확인 응답 없이 보낼 수 있는 데이터의 크기이며 상자이다.
전송 플로우를 간단히 설명하면 다음과 같다.
•프로세스는 TCP 송신 버퍼로 데이터를 밀어낸다(push).
•TCP 송신 버퍼는 수신 버퍼 윈도우와 혼잡 윈도우 변수를 통해 계산하여 TCP 수신 버퍼로 확인 응답 없이 보낼 수 있을 만큼 데이터를 보낸다.
•TCP 수신 버퍼는 수신된 데이터를 보유하고 있다가, 프로세스에서 수신할 준비가 되면 데이터를 당김(pull)에 의해 소비하며, 그에 따라 수신 윈도우도 변경된다.
윈도우 알고리즘
윈도우 알고리즘을 알기에 앞서 몇 가지 용어를 집고 넘어가야 한다.
TCP의 윈도우는
•송신 윈도우 - 수신측의 확인 응답 없이, 한 번에 전달 할 수 있는 바이트 사이즈
•수신 윈도우 - 수신측에서 수신 할 수 있는 바이트의 사이즈(수신 버퍼에 저장할 수 있는 바이트 사이즈)
두 가지가 존재하며 TCP 양방향 통신을 위해서 서버 또는 클라이언트 각각 송신 윈도우, 수신 윈도우를 가져야 하며, 총 4개의 윈도우가 필요하다.
나중에 흐름제어, 혼잡제어를 설명하면 알게되지만
송신 윈도우와 수신 윈도우의 크기는
윈도우 알고리즘 + 송신 윈도우 변수 + 수신 윈도우 변수 + 혼잡 윈도우 변수
맞물려서 계산되게 된다. 복잡하다. 이 부분은 나중에 설명할 예정이다.
일단 기본적인 윈도우 알고리즘으로 크게 두 가지가 존재하며 현대는 혼합된 방식을 사용한다.
•Go-Back-N(GBN) 알고리즘
•Selective-Repeat(SR) 선택적 반복 알고리즘
•Go-Back-N(GBN), Selective-Repeat(SR) 혼합 알고리즘
먼저 해당 알고리즘에 대해 확인 해보고 그 다음 TCP 흐름 제어가 적용된 윈도우에 대해 알아볼 예정이다.
송신측 Go-Back-N과 송신 측 슬라이딩 윈도우
슬라이딩 윈도우는 송신 윈도우 운영 방법 중 하나라고 볼 수 있으며, Go-Back-N 방식의 윈도우와 관련이 있다.
슬라이딩 윈도우로 불리는 이유는 말그대로 윈도우가 변경되는 방식이 슬라이딩(미끄러지는)처럼 작동하기 때문이다.

이론상 Go-Back-N에서 순서 번호 크기만큼 슬라이딩 윈도우의 최대 값은 2^m - 1이다. m은 순서 번호 필드의 비트 수이다.
- 1을 하는 이유는 버퍼나 윈도우를 원형 으로 생각하며, 모드(mod)연산을 이용하여 다시 최초의 순서번호로 돌아와야 하기 때문이다.
슬라이딩 윈도우는 크게 두 가지 연산으로 작동한다. (축소 연산은 제외한다.)
•닫기(Close) - 슬라이딩 윈도우의 왼쪽 커서를 오른쪽으로 옮긴다. 즉 윈도우 사이즈(size)를 줄인다.
•열기(Open) - 슬라이딩 윈도우의 오른쪽 커서를 오른쪽으로 옮긴다. 즉 윈도우 사이즈(size)를 늘린다.
슬라이딩 윈도우와 관련된 변수는 다음과 같다.
•(f) - 미처리(확인 응답 받지 못한)상태인 첫 번째 세그먼트 번호 이다.
•(n) - 다음에 전송할 첫 번째 세그먼트 번호이다.
•(size) - 윈도우의 크기이다.

다음의 그림은 순서 번호와 세그먼트의 관계를 간략히 그림으로 보여준다.
송신 버퍼는 프로세스로 부터 전송할 데이터를 받는다.
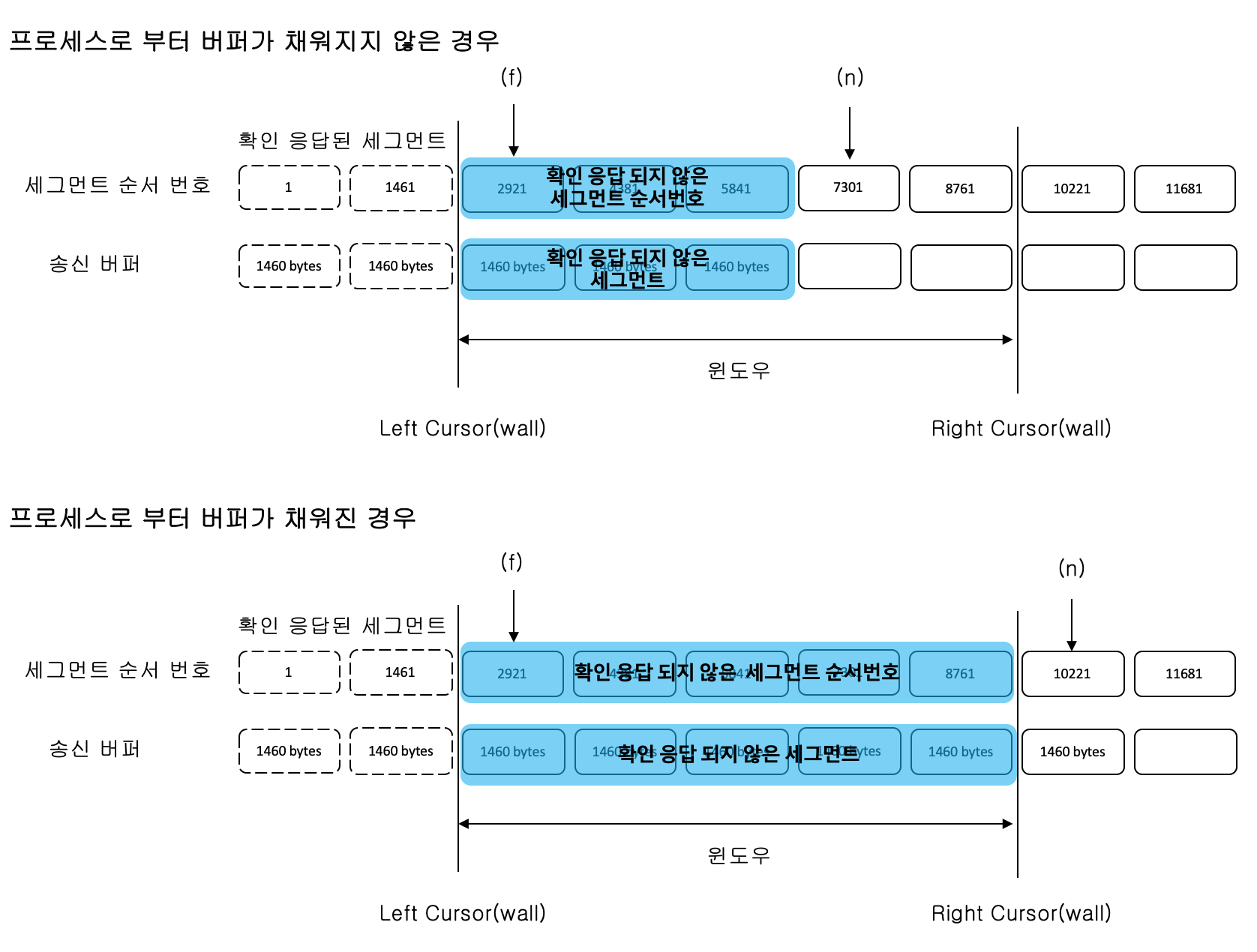
예시로 8192 bytes 버퍼 배열이 존재하며, 순서 번호 비트가 13이면
순서번호의 최대 값은 2^13 -1 (0 ~ 8191) 이며, seqNo mod 2^13 연산을 한다.
1바이트 단위로 논리적인 순서번호(sequence number)가 존재하고,
전송할 1 byte 데이터를 보관하고 있다고 볼 수 있다.
수신측 Go-Back-N과 수신 윈도우
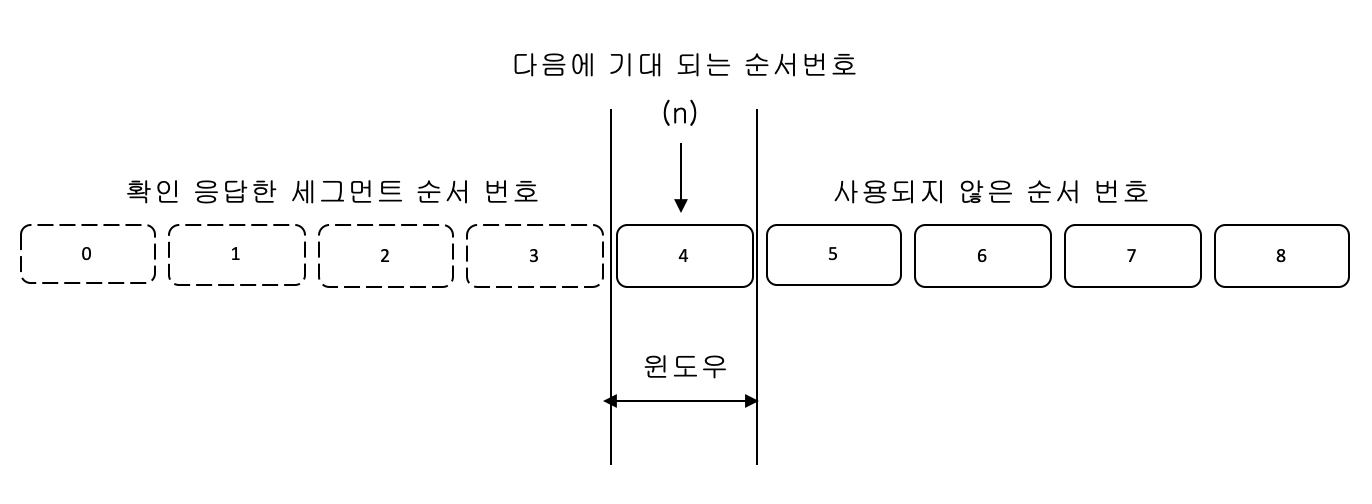
Go-Back-N 방식에서의 수신 윈도우 크기는 항상 1이다.
•(n) - 다음에 기대 되는 세그먼트 순서 번호이다.
올바른 순서번호의 세그먼트를 받았을 때만, 수신 윈도우는 우측으로 이동하며 한 번에 한 칸만 이동한다.
순서 번호는 누적 값이며 다음에 받을 세그먼트의 순서 번호를 뜻한다.
즉 (n)이 4이면, 0부터 3까지는 이미 올바르게 수신되었고 순서 번호 4의 세그먼트를 기대한다고 볼 수 있다.
송수신측 Go-Back-N과 윈도우 시나리오

파란색 칸은 윈도우라고 가정하며,
한 칸당 100 bytes의 데이터를 보유하고 있다고 가정한다.
송신측의 점선칸은 수신측으로 부터 확인 응답 받은 순서번호 및 데이터이며
수신측의 점선칸은 송신측으로 확인 응답을 보낸 순서번호 및 데이터이다.
패킷 손실이 발생하면, 손실 된 순서 번호부터 다시 재전송해야 한다.
ack번호를 잘 확인해야 한다.
송신측 Selective-Repeat과 송신 윈도우
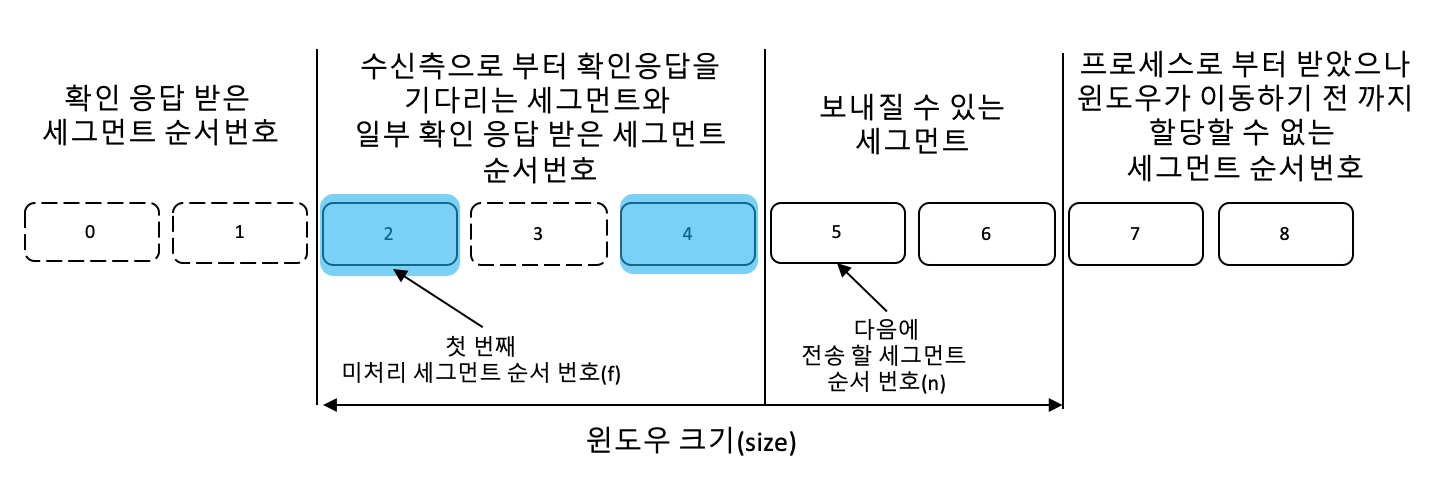
선택적 반복(Selective-Repeat)의 송신 윈도우는 송신 윈도우 운영 방법 중 하나라고 볼 수 있으며 Go-Back-N의 슬라이딩 윈도우와 다르게 운영된다.
이론상, 윈도의 최대 값과 크기는 2^(m-1)이며, Go-Back-N(2^m -1)과 다르다.
선택적 반복에서는 수신측이 순서에 맞지 않는 세그먼트를 보관하고 순서에 맞을 때 까지 확인 응답을 전송한다.
수신측 Selective-Repeat과 수신 윈도우

•(n) - 다음에 기대 되는 수신 받아야 할 세그먼트 순서 번호이다.
Go-Back-N과 가장 큰 차이점은 다음과 같다.
1) 패킷 손실로 인한 수신 세그먼트 순서 번호가 뒤죽박죽 하더라도 일단 수신 받은 데이터를 보관한다.(다만 순서가 올바를 때 까지 프로세스로 전송시키지 않는다.)
2) 윈도우 크기는 송신 윈도우 크기와 동일하다.
3) Go-Back-N에서의 수신측의 확인 응답은 다음에 받아야 할 ackNo를 전송하지만
Selective-Repeat 수신측의 확인 응답은 ackNo = seqNo를 갖는 ACK가 전송된다.
송수신측 Selective-Repeat과 윈도우 시나리오

파란색 칸은 윈도우라고 가정하며,
한 칸당 100 bytes의 데이터를 보유하고 있다고 가정한다.
송신측의 점선칸은 수신측으로 부터 확인 응답 받은 순서번호 및 데이터이며
수신측의 점선칸은 송신측으로 확인 응답을 보낸 순서번호 및 데이터이다.
ackNo는 seqNo와 동일하다.
패킷 손실이 발생하면, 손실된 패킷 순서 번호만 요청한다.
Go-Back-N과 Selective-Repeat 혼합 방식 시나리오

실제로 TCP에서 사용하는 방식으로
Go-Back-N의 슬라이딩 윈도우 방식을 차용하며
Selective-Repeat의 송신 윈도우와 수신 윈도우 크기가 동일한 방식으로 하며
패킷 손실로 인한 오류 회복을 하기 위해 Selective-Repeat의 손실된 패킷만 요구하는 방식을 택하고
오류가 회복 되었을 때는 Go-Back-N의 다음에 기대되는 ackNo를 전송하며
Go-Back-N의 누적 확인 응답 방식을 택한다.(TCP 옵션을 통해 선택적 확인 응답, 누적 확인 응답 방식 다 지원한다.)
또한 이론적으로는 패킷당 타이머가 존재 한다고 하나, TCP 구현체는 하나의 RTO 타이머만 사용한다.
또한 실제로 계산되는 윈도우의 크기는 송신 윈도우 변수, 수신 윈도우 변수, 혼잡 윈도우 변수에 의해 최종계산된다.
오류제어와 관련해서는 아래에서 설명한다.
TCP 흐름 제어 (TCP Flow Control)
TCP 흐름 제어란, 생산자가 데이터를 만드는 속도와 소비자가 데이터를 사용하는 속도의 균형을 맞추는 것이다.
왜 맞춰야 하는가? 수신측의 버퍼 오버 플로우로 인한 패킷 손실이 발생할 수 있기 때문이다.
쉽게 말하자면 수신측의 버퍼 오버 플로우를 막기 위해 송신측의 흐름을 제어하는 방식이다.
그리고 흐름을 제어하기 위해 수신측의 수신 윈도우 변수를 이용한다.

흐름제어는 수신 윈도우 변수(rwnd)에 의해 결정되며 수신 윈도우 변수(rwnd)는 수신 버퍼가 현재 얼마나 데이터를 받을 수 있는 인지 알려줄 때 사용하는 변수이다.
데이터를 생산하는 프로세스와 소비하는 프로세스의 속도가 다르기 때문에, 안정적인 TCP 통신을 위해 수신 측에서 상황을 통보한다.
송신측의 TCP 송신 버퍼 크기와 수신측의 TCP 수신 버퍼의 크기가 다를 수 있으며, 커널의 옵션 파라미터에 따라 달라진다.
속도가 다르다 함은 애플리케이션에서 읽어들여(소비하는) 사용하는 상황과 속도가 다르기 때문에 발생하는 상황이다.
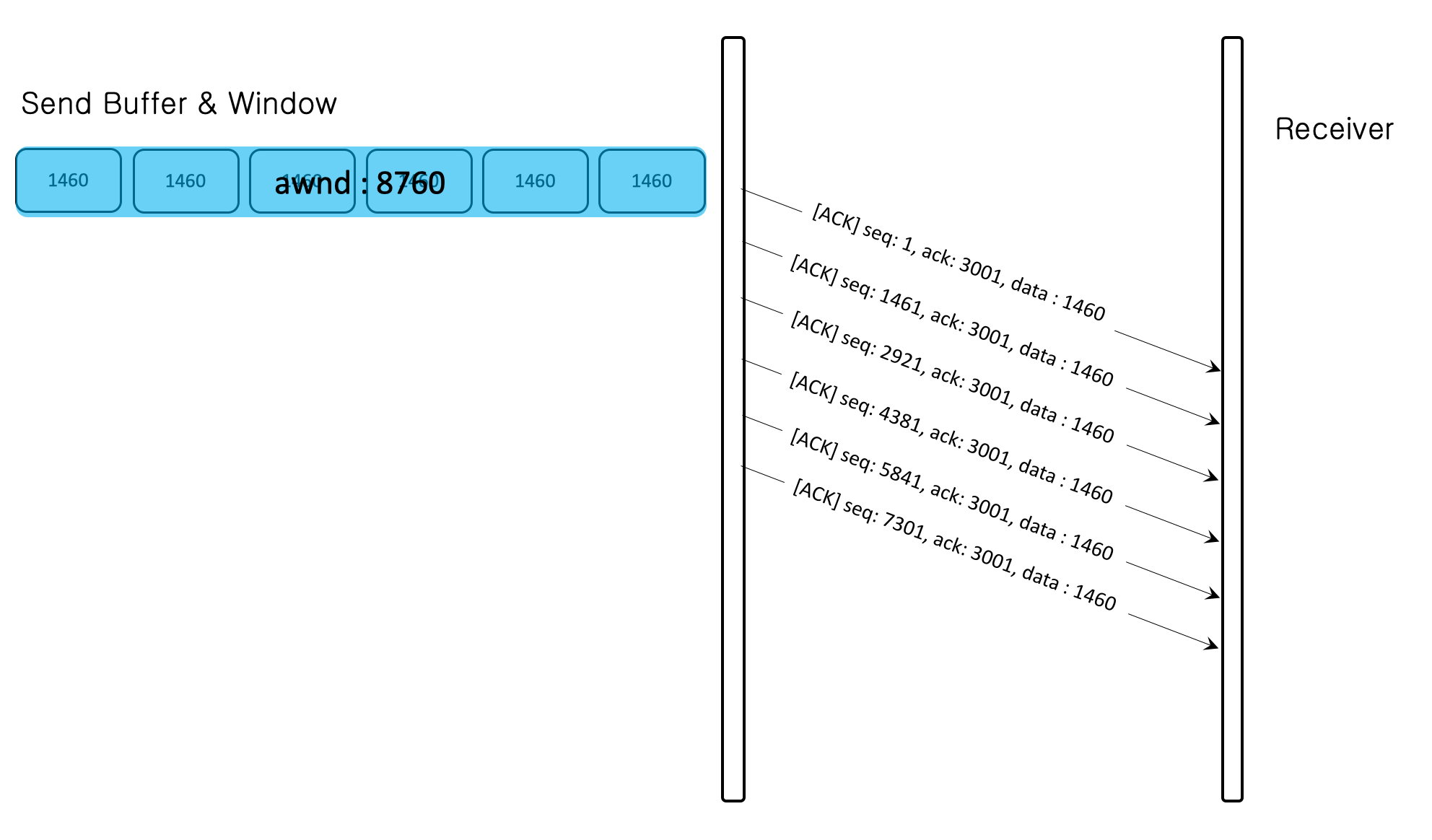
송신측 흐름 제어를 위한 TCP의 윈도우들
송신측 흐름제어를 위한 TCP의 윈도우에 대해서 얘기하려면 윈도우와 관련된 변수를 알아야 하며 총 세 가지가 있다.
•rwnd(Receive Window) - 수신 윈도우 변수 (수신측 흐름 제어와 관련된 변수이다, rwnd = buffer size - number of wating bytes to be pulled)
•cwnd(Congestion Window) - 혼잡 윈도우 변수 (본문 아래의 설명하겠지만 혼잡 제어와 관련된 변수이다)
•awnd(Acutal Window) - 실제 계산되고 전송 가능한 송신 윈도우 변수 (awnd = minimum(rwnd, cwnd))
수신 윈도우와 혼잡 윈도우의 차이는
수신 윈도우는 내부 혼잡(수신측 버퍼-종단)에 대해 제어 하기 위한 윈도우이며
혼잡 윈도우는 외부 혼잡(네트워크-중간)에 대해 제어 하기 위한 윈도우라고
생각하면 좀 더 쉬울 수 있다.
송신 윈도우란?
위에서 간략하게 얘기했듯이,
• 송신 윈도우 변수(awnd)란 수신측의 확인 응답 없이, 한 번에 전달 할 수 있는 바이트 사이즈를 말한다.
• 송신 윈도우 변수(awnd)의 크기는 수신 윈도우 변수(rwnd), 혼잡 윈도우 변수(cwnd)에 의해 계산된다.
• 송신 윈도우가 클 수록 한 번에 더 많은 데이터를 보낼 수 있다.
송신 윈도우는 흐름 제어 + 혼잡 제어 메커니즘에 의해 변경된다.
awnd = minimum(rwnd, cwnd)
일반적인 상황이라면 수신 윈도우는 충분히 크고, 수신측 프로세스에서 수신 버퍼 소비가 레이턴시보다 더 빠르기 때문에 rwnd가 크게 문제되지는 않는다.
다만 진짜 문제는 cwnd인데, cwnd 이 녀석 때문에 실제로 TCP 느린 시작이 발생한다. 보통 OS TCP 커널 파라미터로 cwnd가 1부터 시작한다.
뿐만 아니라 ssthresh(Slow start threshold)라는 특정한 변수가 있는데 혼잡 회피 상태의 임계점으로 cwnd 변수가 빠르게 증가하는 것에 방해가 되기도 한다.
cwnd, ssthresh 변수는 혼잡 제어에서 자세히 얘기한다.
송신 윈도우에 네이글 알고리즘까지 더해지면, 한 번에 확인 응답 없이 전송할 수 있는 데이터는 더 줄어들 수 있다.
송신측의 흐름 제어에 미치는 네이글 알고리즘
if there is new data to send then
if the window size ≥ MSS and available data is ≥ MSS then
send complete MSS segment now
else
if there is unconfirmed data still in the pipe then
enqueue data in the buffer until an acknowledge is received
else
send data immediately
end if
end if
end if출처: https://en.wikipedia.org/wiki/Nagle%27s_algorithm
네이글 알고리즘은 다음과 같다.
1. 전송하기 위한 새로운 데이터가 있으면
1.1 MSS 보다 송신 윈도우 사이즈가 같거나 크고 & 이용할 수 있는 데이터가 MSS 보다 같거나 큰 경우 MSS 만큼 세그먼트를 보낸다.
1.2 그렇지 않다면, 파이프에 여전히 확인 되지 않은 데이터가 있으면
1.2.1 확인 응답을 받을 때 까지 데이터를 버퍼에 더한다.
1.2.2 확인 되었으면 즉시 보낸다.
이 알고리즘을 쉽게 시나리오 사례로 풀면 다음과 같다.
송신측에서 보내야 할 데이터가 4300 bytes 라고 가정한다.
먼저 MSS(Maximum Segment Size) 단위로 전송하므로, 계산하면 세그먼트는 1460 bytes, 1460 bytes, 1380 bytes 세 개로 나뉘게 된다.
그럼 먼저 1460 bytes, 1460 bytes 데이터를 전송하고 1380 bytes 은 전송했던 1460 bytes, 1460 bytes 의 확인 응답이 오기전까지 대기한다.
확인 응답이 오면 즉시 1380 bytes를 전송한다.
그림으로 표현하면 다음과 같다.
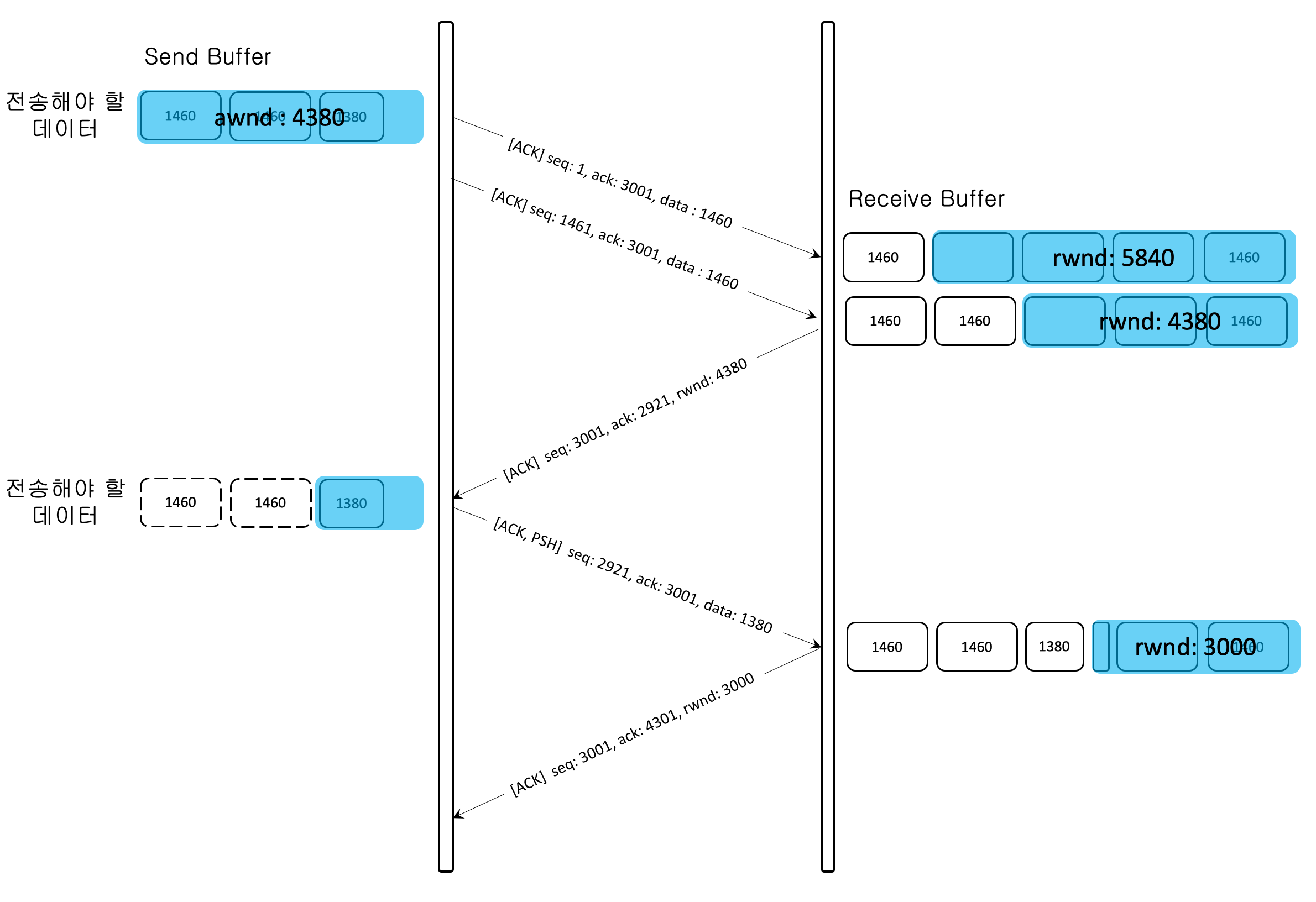
송신 윈도우의 사이즈가 충분함에도 불구하고,
MSS에 도달하지 못했기 때문에 1380 bytes는 이전에 보낸 세그먼트의 확인 응답을 기다리게 된다.
네이글 알고리즘이 아니었다면, 세 개의 세그먼트를 동시에 보낼 수 있었을 것이다.
그럼 왜 네이글 알고리즘을 사용하는가?
네트워크망의 혼잡을 피하기 위해 설계되었다.
만약에 송신측 프로세스에서 송신 버퍼로 작은 데이터 단위로만 계속 밀어(PUSH)낸다고 한다면, 패킷당 IP 헤더와 TCP 헤더에 의해 (IPv4기준 40 bytes, 옵션) 오버헤드 비율이 더 커지게 된다.
예시로 송신측이 수신측으로 90 bytes를 보내되 송신 버퍼가 크게 상관없이 데이터가 채워지자 마자 전송한다고 가정한다.
그리고 프로세스는 세 번에 걸쳐서 데이터를 송신 버퍼로 밀어낸다고 가정한다.
헤더(40bytes) + 데이터(10 bytes),
헤더(40bytes) + 데이터 (20 bytes),
헤더(40bytes) + 데이터 (60 bytes)
데이터 90 bytes를 보내기 위해 헤더 120 bytes의 헤더를 보내야 하는 상황이 발생한다.
즉 네트워크망을 비효율적으로 사용하는 것이다.
실제로 총 전송된 패킷 210 bytes 중 헤더 비율이 약 57%이다.
이런 문제를 해결하기 위해 네이글 알고리즘이 설계되었으나..
네이글 알고리즘의 단점
1) 이전에 보낸 확인 응답을 기다려야 하기 때문에 HOL(Head-Of-Line) 같은 비슷한 문제를 겪을 수 있다. 다만 확인 응답을 받으면 해결되긴 하는 문제이다.
2) 세그먼트 단위의 Round-Trip 횟수로 바라본다면, 네이글 알고리즘을 적용하지 않은 지연 응답 방식과 비교하여 상대적으로 Round-Trip 횟수 가 증가 할 수 밖에 없다.
3) 기다린다는 것은 MSS 만큼의 데이터가 채워질 때 까지 또는 타이머에 의해서 timeout이 될 때 까지 패킷이 즉시 전송되지 않는다는 것을 의미한다.
4) 예외적인 상황에서는 네이글 알고리즘이 오버헤드 비율이 더 높을 수 있다. (미미하긴 하지만)
예시로,
지연 응답 방식에서
•네이글 알고리즘 미적용 시
1) [클라이언트 -> 서버] 데이터전송 : 헤더(40bytes) + 데이터(1460 bytes)
2) [클라이언트 -> 서버] 데이터전송 : 헤더(40bytes) + 데이터 (1460 bytes)
3) [클라이언트 -> 서버] 데이터전송 : 헤더(40bytes) + 데이터 (1460 bytes)
4) [클라이언트 -> 서버] 데이터전송 : 헤더(40bytes) + 데이터 (1380 bytes)
4) [서버 -> 클라이언트] 2)의 확인응답 : 헤더(40bytes)
5) [서버 -> 클라이언트] 4)의 확인응답 : 헤더(40bytes)
결론 : 헤더 240 bytes + 데이터 5760 bytes
•네이글 알고리즘 적용 시
1) [클라이언트 -> 서버] 데이터전송 : 헤더(40bytes) + 데이터(1460 bytes)
2) [클라이언트 -> 서버] 데이터전송 : 헤더(40bytes) + 데이터 (1460 bytes)
3) [클라이언트 -> 서버] 데이터전송 : 헤더(40bytes) + 데이터 (1460 bytes)
4) [서버 -> 클라이언트] 2)의 확인응답 : 헤더(40bytes)
5) [서버 -> 클라이언트] 3)의 확인응답 : 헤더(40bytes) (수신측의 500ms 초과 후 확인응답)
4) [클라이언트 -> 서버] 데이터전송 : 헤더(40bytes) + 데이터 (1380 bytes)
5) [서버 -> 클라이언트] 4)의 확인응답 : 헤더(40bytes)
결론 : 헤더 280 bytes + 데이터 5760 bytes
하지만 네이글 알고리즘이 공유자원(네트워크망)의 혼잡도를 줄이는 것에 도움되는 것은 분명한 사실이다.
TCP 혼잡 제어 (TCP Congestion Control)
TCP 혼잡 제어란, 공유자원인 네트워크망의 혼잡을 악화시켜 통신에 충돌이 나게 하는 것을 줄이고, 한정된 자원을 잘 분배하여 원활히 돌아갈 수 있도록 제어하는 것이다.
공유자원인 고속도로에서 차가 밀리는 것을 생각해보면 쉽다.
모든 가족이 각자의 차를 가지고 고속도로로 나간다면 차는 틀림없이 막힐것이다. 그러나 차량5부제 등 제한을 둔다면 정체가 조금 완화되는 것과 비슷하다고 볼 수 있다.
수 많은 혼잡 제어 알고리즘
•TCP Tahoe and Reno
•TCP Vegas
•TCP New Reno
•TCP Hybla
•TCP BIC
•TCP CUBIC
•Agile-SD TCP
•TCP Westwood+
•Compound TCP
•TCP Proprtional Rate Reduction
•TCP BBR
else...
출처 : https://en.wikipedia.org/wiki/TCP_congestion_control
참고로, AWS EC2 t2.micro의 4.14.70-72.55.amzn2.x86_64 커널에서 사용하는 TCP 알고리즘은 CUBIC이다.
$ sysctl -a
...
net.ipv4.tcp_allowed_congestion_control = cubic reno
net.ipv4.tcp_available_congestion_control = cubic reno
net.ipv4.tcp_congestion_control = cubic
...
혼잡 제어 알고리즘중 CUBIC과 관련된 RFC 문서를 번역한 것이 있습니다. 의역이 많이 없어서 잘 읽히지는 않지만 그래도 혹시나 도움이 될까봐 연결 시켜 놓습니다. 그리고 구글링하다보면 원문과 리뷰 논문도 많습니다. ^^;; 더 확실합니다.
RFC 8312 - CUBIC for Fast Long-Distance Networks 번역
이 글 최종 수정일 : 2020-06-16 문서제목 : RFC 8312 - CUBIC for Fast Long-Distance Networks 번역: 이병록(roka88) 도움주신분들: 파파고, 구글번역 과정 및 남기는 말 이번엔 TCP CUBIC과 관련된 INFOMATION..
roka88.dev
혼잡 윈도우 변수(cwnd)
대부분의 TCP 혼잡 제어 알고리즘은 cwnd를 어떻게 계산하고 설정할 것인지에 고찰이다.
그만큼 TCP에서 성능에 중요한 변수이다.
혼잡 윈도우 변수(cwnd)는 송신 윈도우를 계산하기 위한 변수중 하나이며,
혼잡 윈도우 변수(cwnd)는 MSS(Maximum Segment Size)를 기준으로 한다.
MSS는 IP(Internet Protocol)의 헤더와 TCP 헤더에 의존하기 때문에 IPv4(1460 bytes), IPv6(1400 bytes) 각각 다르며, 세그먼트가 데이터를 가질 수 있는 최대의 크기를 뜻한다.
보통 cwnd를 유리수로 표현한다.
cwnd = 1은 MSS * 1(IPv4기준 1460 bytes)로 볼 수 있다.
cwnd = 2는 MSS * 2(IPv4기준 2920 bytes)로 볼 수 있다.
cwnd = 3은 MSS * 3(IPv4기준 4380 bytes)로 볼 수 있다.
송신 윈도우에 대해 얘기할 때 잠깐 나왔지만, 수신 윈도우가 아무리 커도 혼잡 윈도우 변수가 작을 경우 송신 윈도우 크기는 작을 수 밖에 없다.
혼잡 윈도우 변수(cwnd)는 혼잡 정책에 의해 증가되고 감소된다.
TCP Reno 혼잡 제어 정책
TCP 혼잡 제어 알고리즘 중 Reno를 선택한 이유는 다른 TCP 알고리즘 대비 메커니즘이 상대적으로 쉽기 때문이다.
TCP Reno 혼잡 제어를 살펴보기 위해서는 아래의 내용을 알아야 한다.
•혼잡 감지 - 혼잡을 어떻게 추측하고 감지할 것인가?
•혼잡 윈도우 변수(cwnd) - 중간 네트워크 상의 혼잡을 어떻게 제어하기 위한 변수는 무엇인가?
•느린 시작 임계점 변수(ssthresh - Slow start threshold) - 느린 시작 상태에서 혼잡 상태로 변경하는 임계점 변수
•혼잡 정책 - 혼잡을 어떻게 예방하고, 발생했을 시 어떻게 대처할 것인가?
표준 TCP의 혼잡 제어와 관련된 RFC문서는 아래에서도 확인할 수 있습니다.
RFC 5681 - TCP Congestion Control 번역
이 글 최종 수정일 : 2020-06-27 문서제목 :RFC 5681 - TCP Congestion Control 번역: 이병록(roka88) 도움주신분들: 파파고, 구글번역 과정 및 남기는 말 이번엔 TCP Congestion(표준 TCP 혼잡 제어)과 관련된..
roka88.dev
TCP Reno 혼잡 감지
TCP Reno의 혼잡 감지는 단순하다.
1) RTO(Retransmission time-out) 타이머에 의해 계산되는 시간 내에 세그먼트가 도착 하지 않았을 경우, 혼잡에 의해 세그먼트가 유실 되었다고 가정한다.

2) 수신측의 동일한 ackNo의 확인 응답을 송신측에서 세 번이상 수신 했을 경우는, 이전에 보냈던 세그먼트가 혼잡에 의해 세그먼트 유실 또는 손실이 되었다고 가정한다.
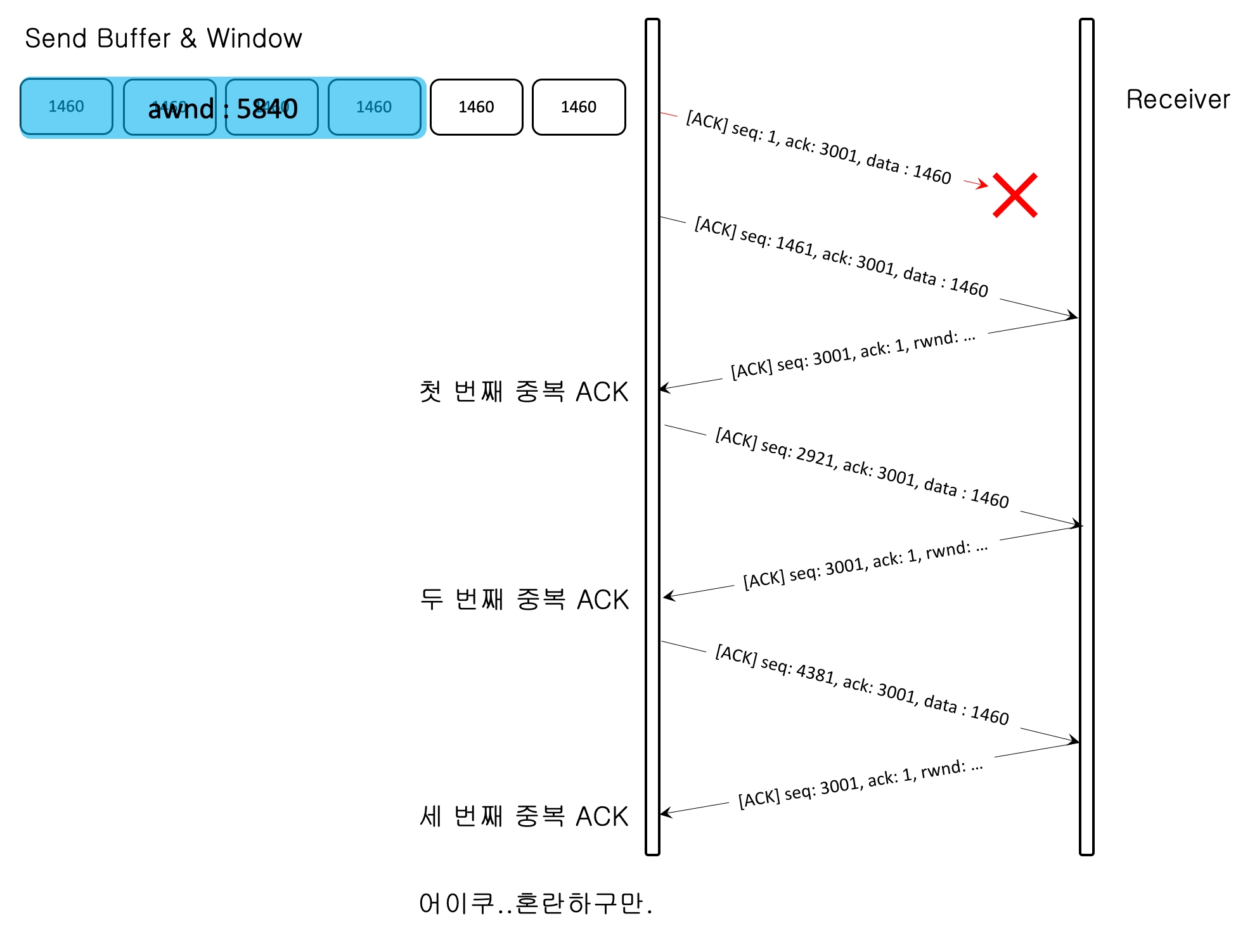
다른 TCP 알고리즘은 혼잡 감지 방법이 다를 수 있다.
(CUBIC은 ECN-Echo 확인 응답이나, 동일 패킷 발생 시 혼잡이 발생했다고 가정한다.)
동일한 세 개의 ACK 수신의 의미는?
일시적인 네트워크 혼잡으로 인해 세그먼트가 손실 했을 가능성을 포함한다.
즉, Time-out 전에 세 개의 동일한 ACK(복사본)를 정상적으로 수신했다는 얘기는 네트워크 혼잡이 완화되었다고도 볼 수 있다.
그러므로 TCP Reno에서는 TCP Taho와 다르게 빠른 회복 상태를 추가하여, 원활한 세그먼트 전송을 유지한다.
TCP Reno 혼잡 상태
혼잡 상태는, 혼잡 제어 알고리즘을 구현한 구현체에 따라 다르다.
TCP Reno의 혼잡 상태는 세 가지의 상태로 구분한다.
•느린 시작(Slow Start) - 혼잡 회피 상태가 될 때 까지 cwnd 증가 방식을 지수 증가 방식으로 한다.
•혼잡 회피(Congestion Avoidance) - 혼잡을 회피하기 위해 미리 예방하는 것과 비슷하다. cwnd 증가 방식을 가산 증가 방식으로 한다.
•빠른 회복(Fast Recovery) - 느린 시작 상태 또는 혼잡 회피 상태에서 특정 상황이 발생하면(동일한 ACK 중복 수신) 빠른 회복 상태로 변경된다.
해당 상태가 있는 이유는 Taho TCP는 빠른 회복 상태가 없이 세그먼트가 타임아웃 또는 혼잡이 완화되어 동일한 ACK 중복 수신 할 시에도 cwnd를 초기화 수준으로 만드는 문제를 보완하기 위해 만들어졌다.
TCP Taho, TCP Reno에서 느린 시작 임계점 변수(ssthresh - Slow start threshold)는 별게 없다.
혼잡 정책에서 사용하는 변수로서 cwnd가 ssthresh보다 크거나 같으면(cwnd >= ssthresh) 느린 시작 상태에서 혼잡 회피 상태로 정책이 변경된다.
TCP Reno와 관련하여 인터넷에 떠도는 TCP 혼잡 상태 천이도가 있기는 하나 개인적으로 sudo 코드로 작성해봤다.
코드 좋아하는 사람은 이게 더 이해가 빠를 수 있다.
확인 응답 수신 또는 타이머에 의해 상태 체크
if 느린 시작(Slow Start) 상태인가? {
if 확인 응답이 타임 아웃되었는가? {
ssthresh = cwnd / 2
cwnd = 1
} else if 세 개의 중복된 확인 응답을 받았는가? {
ssthresh = cwnd / 2
cwnd = ssthresh + 3
빠른 회복(Fast Recovery) 상태로 변경
} else {
cwnd = cwnd + 1
if cwnd >= ssthresh {
혼잡 회피(Congestion Avoidance) 상태로 변경
}
}
} else if 혼잡 회피(Congestion Avoidance) 상태인가? {
if 확인 응답이 타임 아웃되었는가? {
ssthresh = cwnd / 2
cwnd = 1
느린 시작(Slow Start) 상태로 변경
} else if 세 개의 중복된 확인 응답을 받았는가? {
ssthresh = cwnd / 2
cwnd = ssthresh + 3
빠른 회복(Fast Recovery) 상태로 변경
} else {
cwnd = cwnd + (1/cwnd)
}
} else if 빠른 회복(Fast Recovery) 상태인가? {
if 확인 응답이 타임 아웃되었는가? {
ssthresh = cwnd / 2
cwnd = 1
느린 시작(Slow Start) 상태로 변경
} else if 동일한 확인 응답인가? {
cwnd = cwnd + 1
} else {
// 새로운 확인 응답 번호를 수신시
cwnd = ssthresh
혼잡 회피(Congestion Avoidance) 상태로 변경
}
}
아래의 그림은 TCP Taho와 TCP Reno의 차이를 잘 보여준다.

TCP Reno의 혼잡 상태 변경은 다음과 같다.
1) 1 ~ 4 RTT까지 느린 시작 상태이며 cwnd가 가산 증가 방식이다.
2) 5 RTT 부터 cwnd가 임계점(ssthresh)에 도달함으로서 혼잡 회피 상태로 돌입하며,
혼잡 윈도우 계산 방식이 cwnd = cwnd + (1/cwnd)로 변경된다.
3) 8 RTT 혼잡에 의해서 세 개의 동일한 ACK를 수신하면 빠른 회복 상태로 돌입하며,
Reno는 ssthresh = cwnd / 2, cwnd = ssthresh + 3로 설정된다.
4) 9 RTT 부터는 새로운 ACK를 수신 받아 혼잡 회피 상태로 변경된다.
5) 16 RTT에서 Time-out이 발생하였고 그로 인해 느린 시작 상태로 돌입하며,
ssthresh = cwnd / 2, cwnd = 1로 설정된다.
6) 20 RTT 부터 cwnd가 이 임계점(ssthresh)에 도달함으로서 혼잡 회피 상태로 돌입하며,
혼잡 윈도우 계산 방식이 cwnd = cwnd + (1/cwnd)로 변경된다.
TCP 오류 제어
TCP 오류 제어란, 훼손된 패킷을 감지 하고 중복 수신된 확인 후 폐기하며, 손실된 패킷은 재전송하고 순서에 맞지 않는 세그먼트를 버퍼에 저장하는 일을 한다.
TCP는 신뢰성 있는 프로토콜로 불린다. 그 이유는 아래와 같은 일을 통해 프로세스가 정상적으로 패킷을 수신할 수 있도록 도와주기 때문이다.
•훼손된 패킷의 감지 및 폐기(수신자)
•중복 수신 패킷을 확인 후 폐기(수신자)
•분실된 패킷이 도착할 때 까지 순서에 어긋나게 들어온 패킷을 버퍼에 저장(수신자)
•손실되거나 제거된 패킷을 확인 후 재전송(송신자)
그리고 TCP 오류 제어는 크게 세 가지 도구를 통해 수행된다.
•검사합(Check Sum) - 세그먼트내에 있는 검사합 필드를 통해 패킷이 훼손되었는지 확인한다.
•확인응답(Acknowledgement) - 세그먼트의 수신을 알려주기 위해 확인 응답을 사용한다.
•타임아웃(Time-out) - 송신 TCP는 연결당 재전송 타임아웃(RTO, retransmission time-out) 타이머를 사용하여 패킷의 재전송시기를 가늠한다.
검사합
훼손된 패킷의 감지는 검사합을 통해 정상적인 패킷 유무를 확인하며 손실 됬을 경우 폐기한다.
본문에서는 검사합 비트를 어떻게 만드는지 다루지 않는다.
확인 응답 정책과 방식
확인 응답은 크게 5가지 정책이 있으며 두 가지 확인 응답 방식(누적, 선택적)이 존재한다.
1. 5가지 정책
1) 이전에 수신된 세그먼트에 대해 확인 응답을 한 경우 또 다른 다른 세그먼트가 도착하거나 500ms의 시간이 지나기 까지 ACK 세그먼트의 전송을 보류한다. (지연된 확인 응답방식)
이유는 빈번한 확인응답으로 인한 트래픽 혼잡을 줄이기 위함이다.
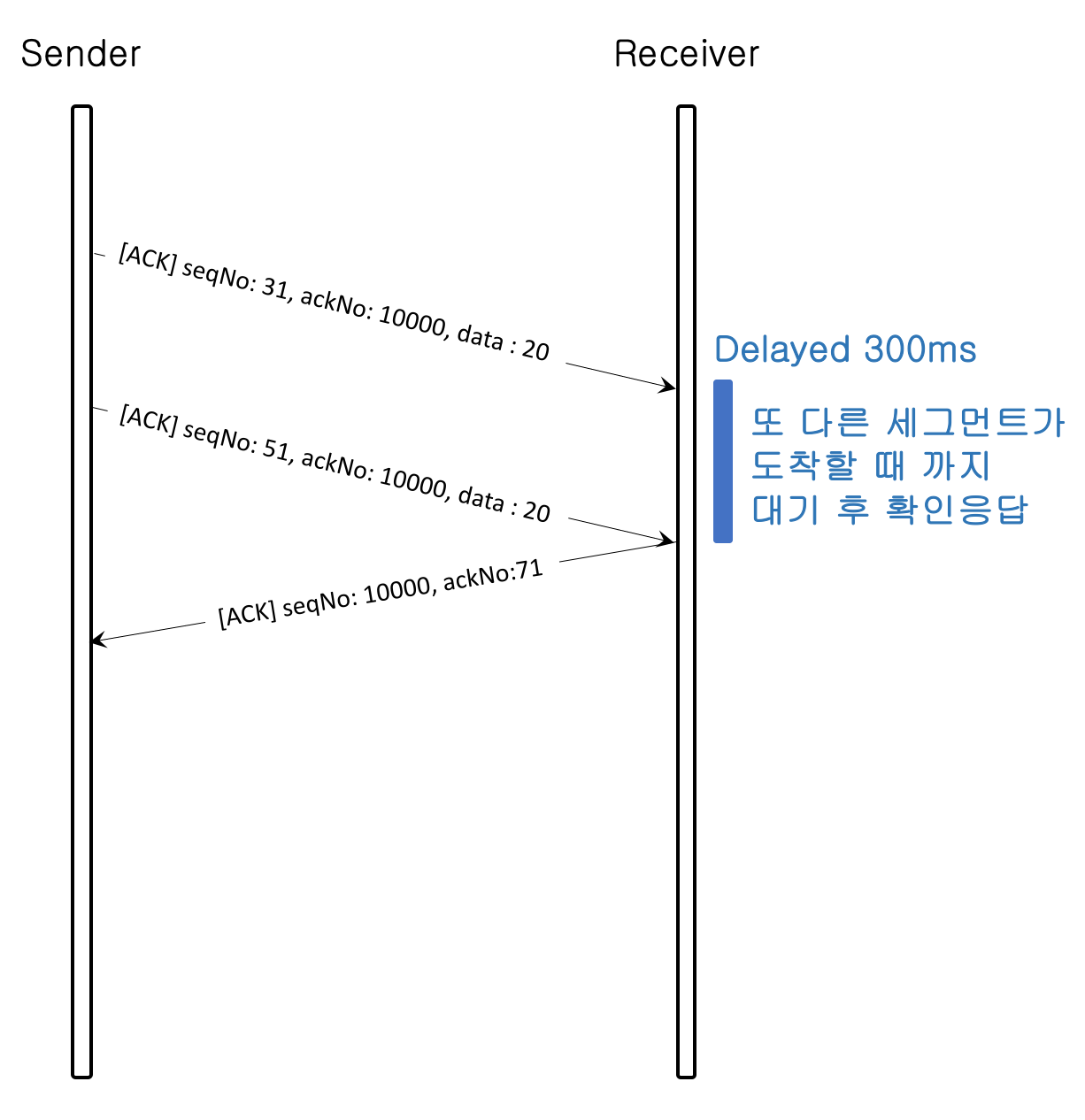
2) 시간 500ms 이내에 새로운 세그먼트가 도착하지 않을 경우 그 즉시 수신한 세그먼트에 대해 확인 응답을 보내야 한다.
이유는 오랫동안(상대적) 확인 응답을 보내지 않는 경우 송신측에서 세그먼트 재전송을 할 수 있기 때문이다. 세그먼트 재전송은 트래픽 혼잡을 유발 할 수 있다.

3) 지연과 상관없이 2개 이상 확인 응답 하지 않은 세그먼트를 보유하지 않는다.
이유는 빠른 확인응답을 통해 송신측에서 다음 세그먼트를 전송할 수 있도록 하기 위함이다.
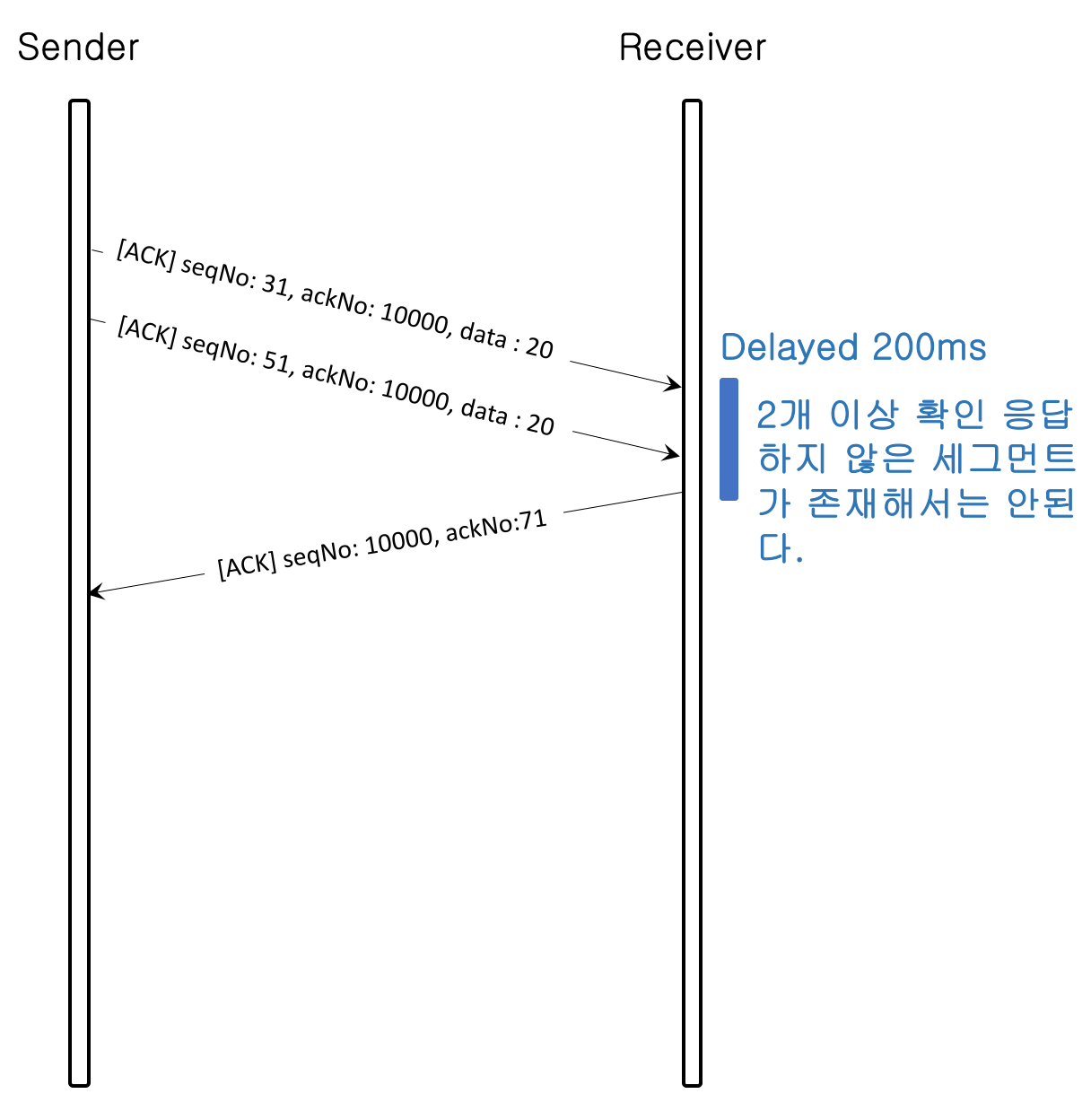
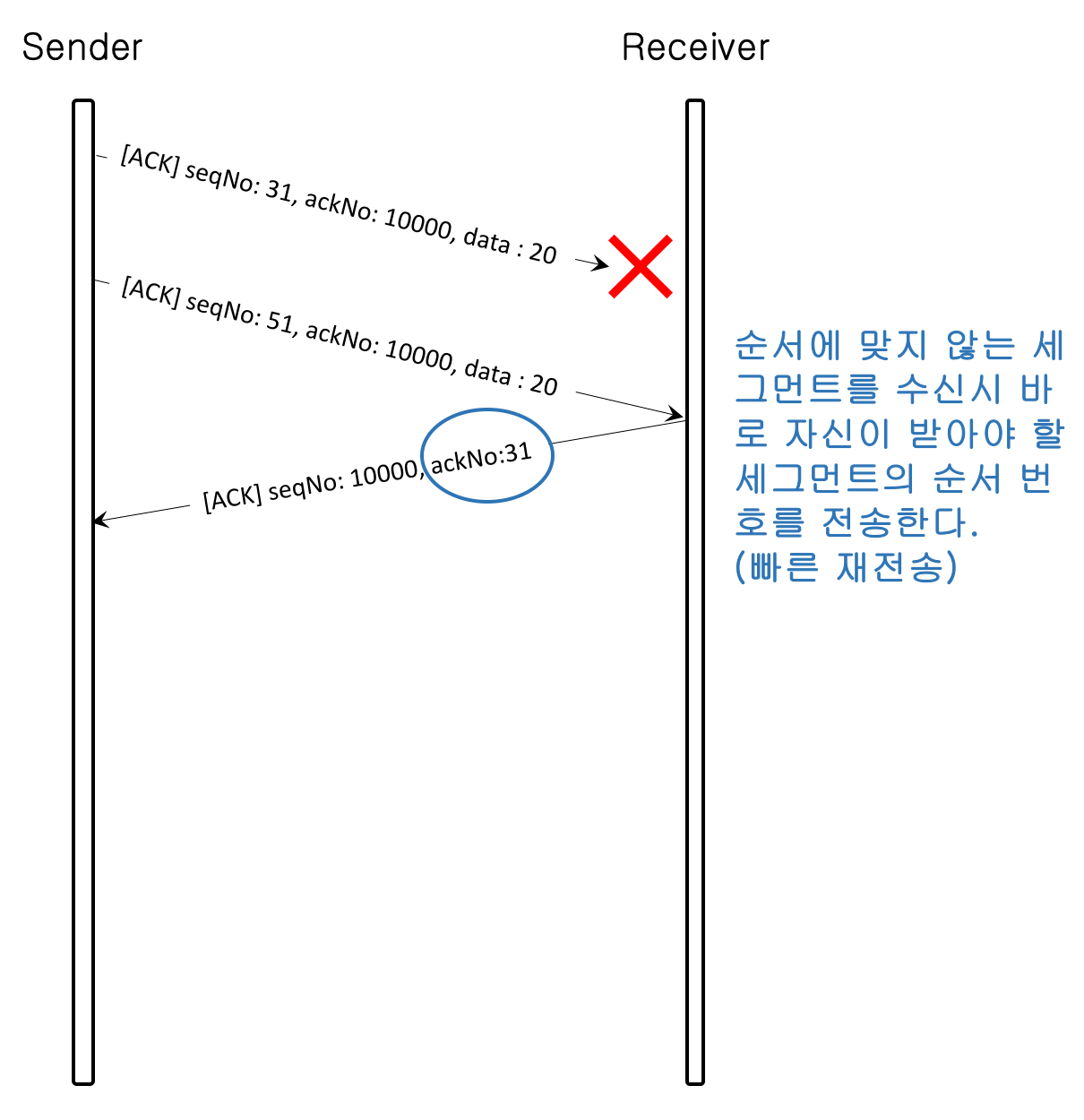
4) 순서에 맞지 않는 세그먼트를 수신 시 바로 수신측이 올바르게 받아야 할 세그먼트 순서 번호를 전송한다.(빠른 재전송)
이유는 송신측에게 잘못된 세그먼트를 빠르게 알려줌으로써 송신측에서 바로 정상적인 패킷을 재전송할 수 있기 때문이다.
5) 네트워크 혼잡으로 인해 재전송된 세그먼트에 의해 중복된 세그먼트를 수신하거나, 그 외의 이유로 인한 재전송된 세그먼트에 의해 중복된 세그먼트를 수신하는 경우 자연스럽게 중복된 세그먼트는 폐기시킨다.

2. 확인 응답 방식(ACK, SACK)
확인 응답 방식은 크게 두 가지가 존재한다.
확인 응답 방식이란, 확인 응답 번호를 어떻게 보낼지에 대한 확인 응답 방식으로 이해하면 조금 더 쉽다.
이 본문 위의 '윈도우 알고리즘'과 관련된 부분으로
Go-Back-N 방식의 누적 확인 응답(ACK),
Selective-Repeat 방식의 선택 확인 응답(SACK) 이라고 볼 수 있다.
현대의 TCP 구현체(Implements)들은 SACK은 TCP 옵션을 통해 사용할 수 있도록 적용되어있다.
1) 누적 확인 응답(ACK)

누적 확인응답 방식은 확인 응답의 ackNo까지는 정상적인 순서로 수신되었다는 것을 알리며 송신측에서 보내야 할 다음의 순서 번호까지 알려주는 역할을 한다.

손실된 패킷이나 훼손된 패킷을 받으면 누적 확인응답 방식은 폐기 또는 순서에 맞지 않는 세그먼트로 버퍼에 보관하는 방식을 사용하는데
다음과 같은 시나리오로 적용된다.
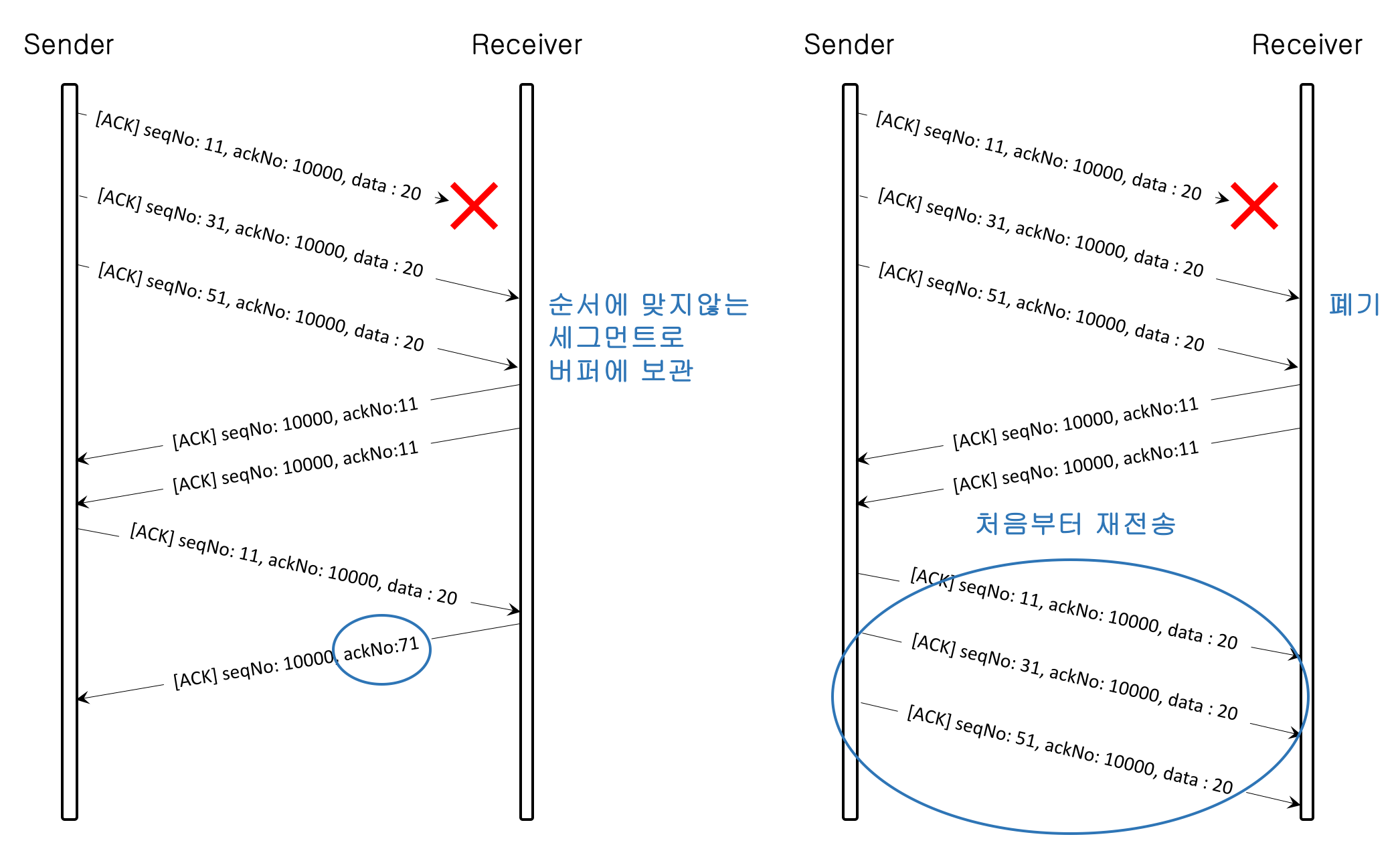
위의 그림은
송신자 측에서 손실된 패킷만 보내며 수신자 측은 순서에 맞지 않는 세그먼트로 버퍼에 보관하는 방식과
송신자 측에서 손실된 패킷 번호 부터 처음 부터 재전송하며 수신자 측은 순서에 맞지 않는 세그먼트를 폐기 하는 방식으로
나뉠 수 있다.
2) 선택 확인 응답(SACK)

누적 확인응답 방식과 다르게 확인 응답의 ackNo는 정상적으로 수신한 ackNo = seqNo를 전송하는 방식이다.
다음에 보내야 할 순서 번호를 알려주지는 않는다. 내가 아는 한 지연된 확인 응답 방식을 사용할 수 없는 구조이다.
지연된 확인 응답 방식을 적용하려면 수신측이 세그먼트 번호를 누적으로 받은 후 다음에 보내야 할 순서 번호를 알려줘야 하는 방식(하나의 확인 응답만 보내도 됨)인데 선택 확인 응답 방식은 자신이 받은 세그먼트에 대해서 하나씩 확인응답 해야하는 상황이기 때문이다.
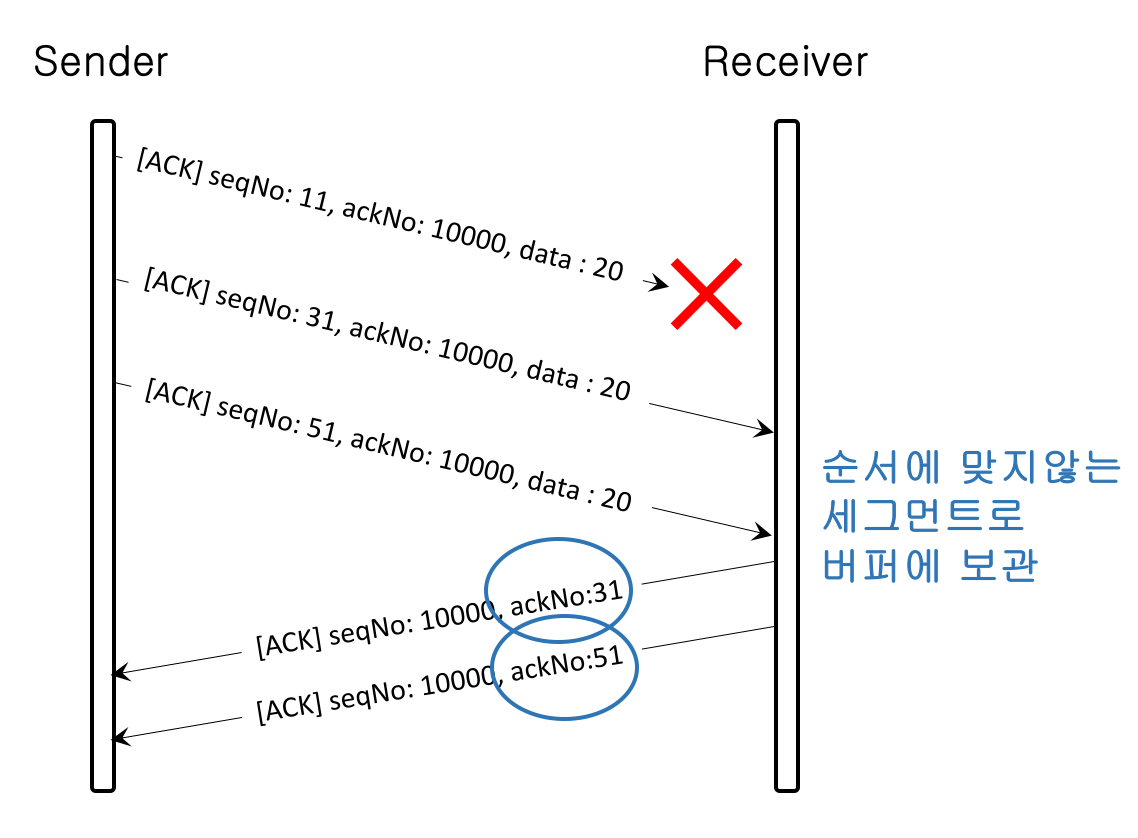
손실되지 않은 세그먼트에 대한 확인 응답만 전송하기 때문에, 확인 응답이 도착하지 않은 세그먼트의 ackNo는 송신자측의 재전송 타이머(RTO Timer)에 의해 세그먼트를 재전송함으로 손실된 세그먼트에 대한 복구를 한다.
타임아웃
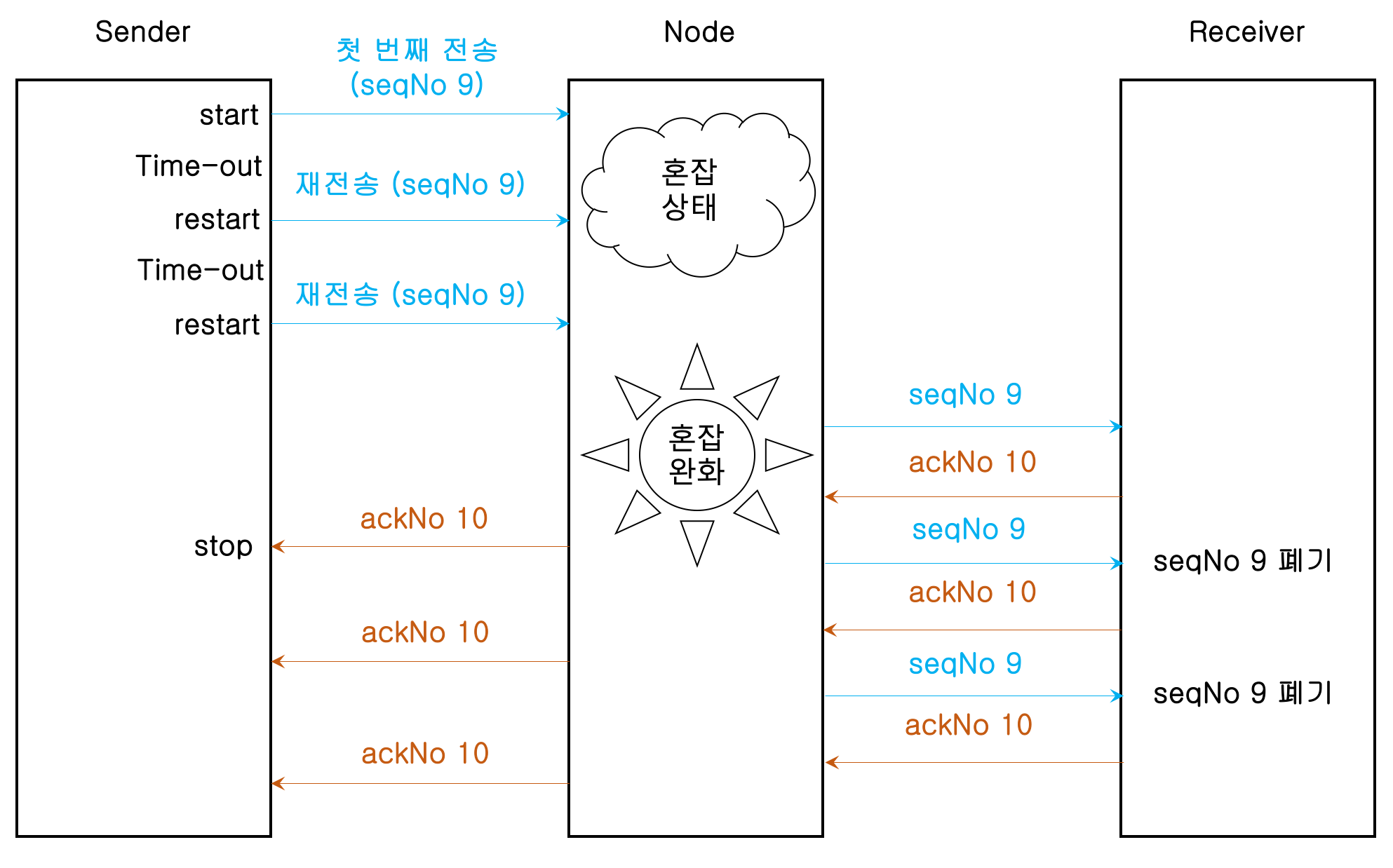
타임아웃은 송신측의 재전송 타이머(Retransmission Timer, RTO Timer)에 의해 타임아웃을 체크한다.
이론상 세그먼트당 RTO 타이머가 개별적으로 존재해야 한다고 했으나 현재 TCP 구현체들은 커넥션당 하나의 RTO 타이머를 사용하여 계산한다.

하나의 RTO 타이머는 기본적으로 송신측에서 세그먼트 전송 시 타이머가 실행되며, 수신측으로부터 확인 응답을 받으면 타이머는 종료된다. 다만 세그먼트 손실이 발생 후 타이머의 타임아웃 전에 송신측이 수신받아야 할 확인 응답 번호가 아닌 경우 세그먼트 손실로 확인되며 즉시 세그먼트를 재전송하며 타이머의 시간은 재시작 된다. 정상적인 확인 응답을 수신시 타이머는 종료된다.
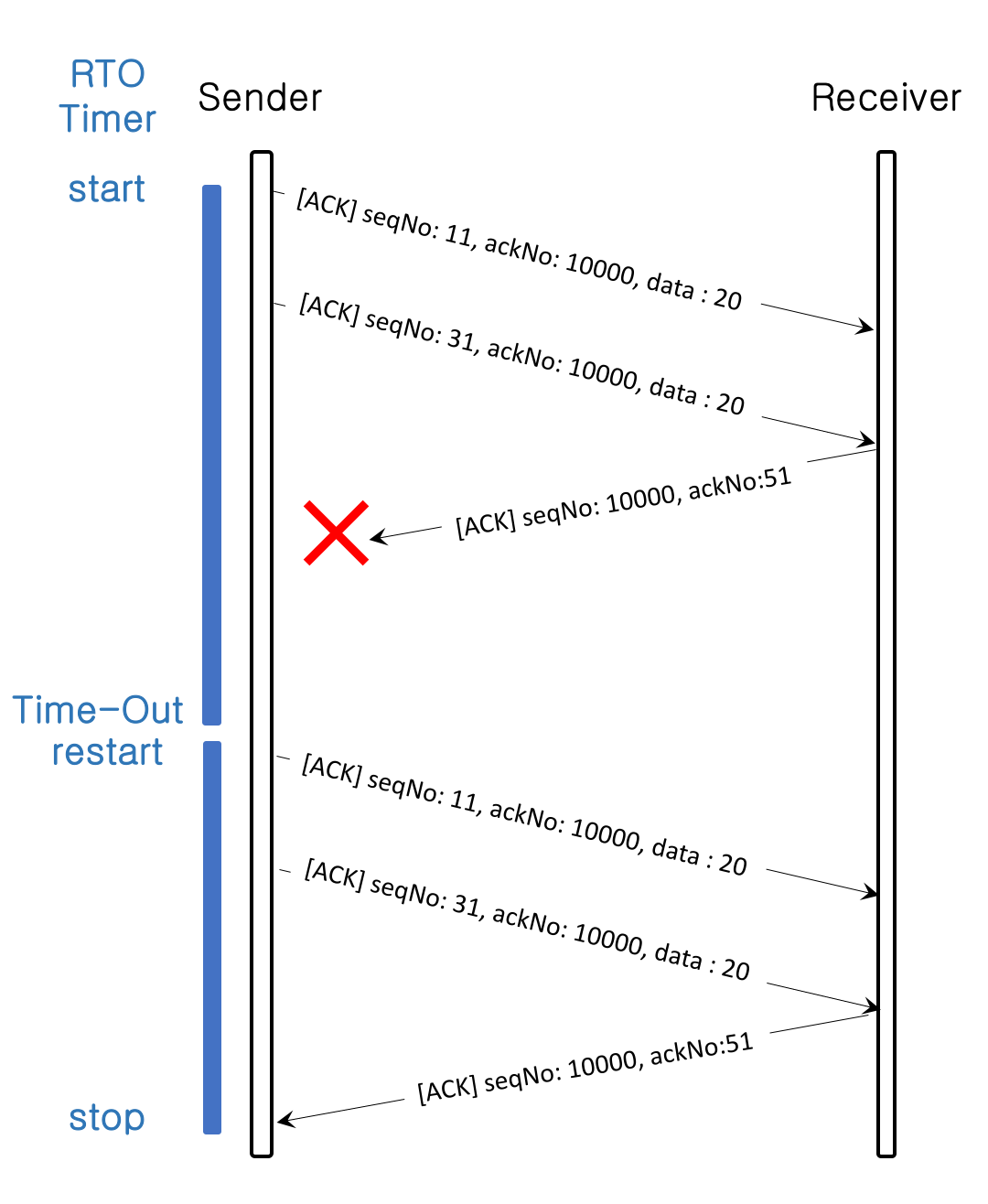
수신측의 확인응답이 손실되는 경우가 존재한다. 이 경우는 재전송 타이머에 의해 타임아웃이 발생하며, 확인 응답 받지 못한 경우(누적 방식인 경우) 다시 세그먼트를 재전송한다. 타이머에 의해 세그먼트 재전송으로 인한 오류가 보정되며 정상적인 확인 응답을 수신 시 타이머는 종료된다.
기타 - OS TCP 파라미터
AWS EC2 t2.micro의 TCP 파라미터는 다음과 같다. 참고용이다.
기본 Default TCP 혼잡제어 알고리즘은 TCP Cubic으로 설정되어있는 것을 알 수 있다.
// AWS EC2 t2.micro의 (4.14.70-72.55.amzn2.x86_64) 정보
$ sysctl -a
...
net.core.rmem_default=212992 // 모든 연결 유형의 OS 기본 read 버퍼 크기
net.core.rmem_max = 212992 // 모든 연결 유형의 OS 최대 read 버퍼 크기
net.core.wmem_default = 212992 // 모든 연결 유형의 OS write 버퍼 크기
net.core.wmem_max = 212992 // 모든 연결 유형의 OS 최대 write 버퍼 크기
net.ipv4.tcp_mem = 10623 14165 21246
// 하드웨어 메모리 스펙에 따라 자동으로 설정.
// TCP 스택 메모리 사용량을 어떻게 할지. (리눅스 기본 page 단위 4096 bytes)
// 첫 번째 값 커널의 TCP 낮은 임계값 페이지 수(min) 43,511,808 bytes
// 두 번째 값 커널에서 TCP 메모리 사용량을 줄이기 위한 시점 페이지 수(pressure) 58,019,840 bytes
// 세 번째 값 커널에서 TCP 최대로 사용할 수 있는 메모리 페이지 수(max) 87,023,616 bytes
net.ipv4.tcp_rmem = 4096 87380 6291456
// 첫 번째 값 각 TCP 최소 수신 버퍼 공간
// 두 번째 값 각 TCP 기본 수신 버퍼 공간
// 세 번째 값 각 TCP 최대 수신 버퍼 공간
net.ipv4.tcp_wmem = 4096 20480 4194304
// 첫 번째 값 각 TCP 소켓에 사용할 수 있는 최소 TCP 송신 버퍼 공간
// 두 번째 값 각 TCP 소켓이 사용할 수 있는 기본 버퍼 공간
// 세 번째 값 각 최대 TCP 송신 버퍼 공간
net.ipv4.tcp_window_scaling = 1
// 윈도 스케일링 옵션 RFC 1323
// 수신 윈도우 사이즈를 65,535 -> 1gb까지
// 커넥션 설립시 세그먼트에 표기된 윈도 사이즈 16비트와
// TCP 옵션을 통해 얼마나 시프트 연산을 해야 할지 알려 줌으로 써 최대 수신 윈도 사이즈를 확장할 수 있다.
net.ipv4.tcp_adv_win_scale = 1
net.ipv4.tcp_app_win = 31
net.ipv4.tcp_allowed_congestion_control = cubic reno
net.ipv4.tcp_available_congestion_control = cubic reno
net.ipv4.tcp_congestion_control = cubic
남기는 말
해당 문서를 작성기간이 꽤 오래걸렸습니다. 최초 등록일이 2020-06-09 였는데 바빠서 이제야 결국 어느정도 완성해서 글을 올립니다.
아쉬운 점은 TCP의 넣고 싶은 점을 다 넣지는 못했습니다. 지금도 충분히 내용이 길기도 해서 별도의 문서로 남길까 합니다.
(그리고 할 일이 많습니다....흐어아엉...ㅠㅠ)
예를들어
RTO 타이머 계산법
클라크의 해결책
송,수신윈도우와 신드롬문제
발생할 수 있는 TCP 시나리오
다른 TCP 혼잡제어 알고리즘과 차이
else.
아쉬운 점이 많은 문서이지만 다음으로 넘기고 이만 물러가겠습니다.^^
참고
Behrouz A, Forouzan. 데이터 통신과 네트워크 5판. MCGraw-Hill, 2013
https://wwwx.cs.unc.edu/~sparkst/howto/network_tuning.php
https://meetup.toast.com/posts/53
https://www.ibm.com/support/knowledgecenter/linuxonibm/liaag/wkvm/wkvm_c_tune_tcpip.htm
https://www.jslab6.edu.cn/media/jslab/paper/38/38kJaNCG6ltV7v2pPETxKow3SDmZrQ45.pdf
'교육자료' 카테고리의 다른 글
| Docker 명령어 정리(개인) (0) | 2020.07.26 |
|---|---|
| TCP의 흐름제어, 오류제어, 혼잡제어 예제 시나리오 (1) | 2020.06.09 |
| 온디맨드 이미지 리사이징 (Ondemand Image Resizing) 원리 및 예제 (11) | 2020.02.09 |
| AWS를 이용한 간략 지속적 통합 예제, 무중단 배포 자동화 CI & CD, CodeBuild, CodeDeploy, CodePipeline (0) | 2020.01.05 |
| 기본 정렬 알고리즘의 종류와 정리 (1) | 2020.01.04 |


